One Year Journey as a Software Developer

Here is how I wrote this blog post.
I remembered things I contributed last year.
made them into points and started expanding on how anyone can implement/learn that.
Then realised the blog post is getting long :)
Anyways, Hey everyone, I am Hrithwik, I am a Software Developer From Bangalore working at an Indian EdTech Company.
I started my journey as a Software Developer professionally last year and these are some of the things I learnt last year.
If you are someone who is going to work with MongoDB and Javascript, This blog post can help you learn a thing or two, just skim through the Table of Contents and choose any heading and you will learn something.
Learnt to use Debugger in VSCode
For a guy who used to write a lot of console logs
Learning to use a debugger, was the first coolest thing I learnt.
Initially, I had set up ts-node and had done a bunch of things to set up a debugger in every project I worked on VSCode.
Then discovered that there is an easier way to run a debugger in VSCode.
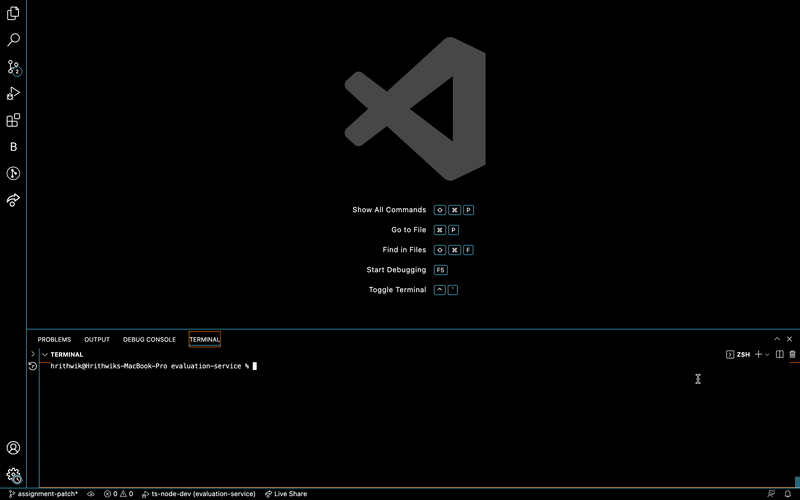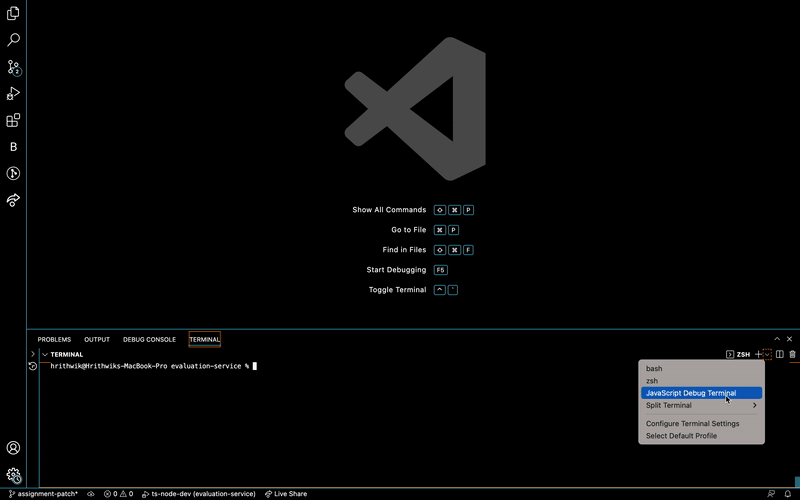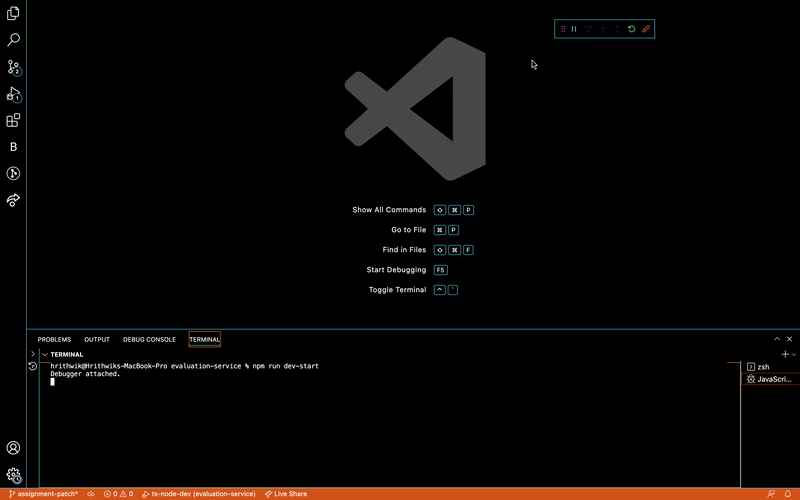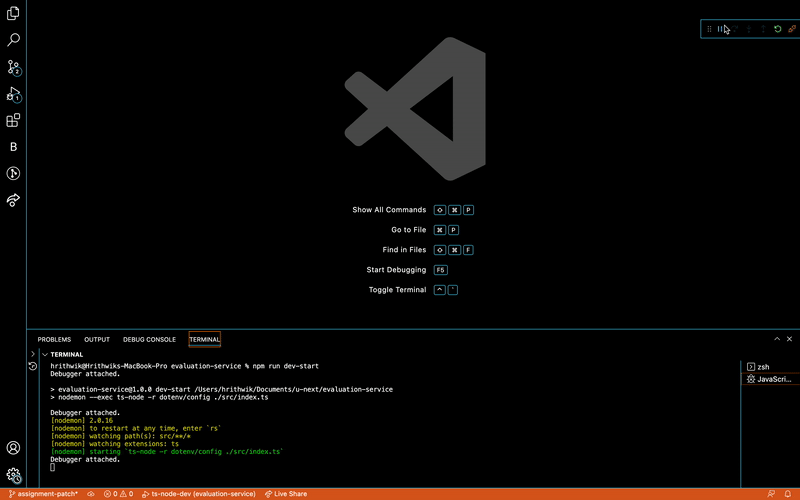
That's it :)
Working with Typescript
I was a developer who started coding backend with python(flask) and then got introduced to Node.js with javascript
While I thought this is good, I then discovered Typescript.
Typescript is javascript but with types, it's pretty easy to get started with the basics, but once you start writing code, you realise how much more is there to learn.
Here is what I did
Learnt some basics like data types and interfaces to contribute to the codebase in my first week.
Started using some advanced concepts like Generics and keyof in the coming weeks
Then got busy with shipping more instead of wasting time with types. (haha jk. I actively use TS and explore different open source repos like excalidraw, zod etc to get better)
The amount of run time errors typescript can save you from is enormous.
But do note that once the codebase get's huge, your type server starts acting weird, You might not get type recommendations immediately, basically, the IDE experience becomes slower, I manually restart the server most of the time to get the type get reflected immediately
GitHub 2 Branch Strategy
Well, I knew how to use GitHub and some basic commands, but learnt a new thing called GitHub 2 branch strategy.
Initially, when I joined my first company, the approach was like this, I used to create a branch from develop and push all my changes to develop. Then every X weeks once, all the code from develop used to go to main.
Life was simple when we did this, but this has a major flaw. At one point your master branch will have all the code which is in develop and some code which is in develop is not usually stable.
So our Architect came up with a new strategy which we follow to raise PRs.
The idea is simple, we have 2 Branches, Develop and Main.
Main has verified non-buggy code.
Develop has new features which are yet to be tested fully.
You take a branch from Main and create a Feature branch, Push all the code to your feature branch and raise a PR to develop. If it has no merge conflicts, good :)
If it does have merge conflicts, you don't take a pull from develop to your feature branch but
You create a branch from develop
Name it like dev/{featureBranchName}
You merge your feature branch to the new develop branch
You will get merge conflicts, resolve them and raise a PR to develop and delete the source branch(dev/{featureBranchName})
Then test the feature thoroughly in develop and then raise a PR to main, If you get merge conflicts, take a pull from main and resolve them.
The idea is simple, Your feature branch should only have the code which you have written and the code which is in main.
Atomic Updates using Transactions in Mongo
I will have an entire section on MongoDB Learnings but wanted to share about this before I started sharing other things
When I was working on personal projects, I had never thought about transactions or Atomic Updates. I had just read the theory in my engineering and never thought about it in the NoSQL context.
Although update and findAndModify Queries are Document Level Atomic, they by default aren't collection level atomic.
What's an Atomic Update ?
Let's say you have an API which is changing the data in two different collections, If the update in one collection fails, the other one should not be stored as well.
For Atomic Updates to happen through different collections we have to use transactions.
How do we make this work in Mongoose?
const cls = require('cls-hooked');
const mongoose = require('mongoose');
const ns = cls.createNamespace('session'); // any name works
async function initialiseTransaction() {
const session = await mongoose.startSession();
session.startTransaction();
ns.set('MONGOOSE_SESSION', session);
return session;
}
The initialiseTransaction Function will create a session object. You can run this while starting the app and use something like cls-hooked , which is local-storage for nodejs to share this session object to any part of your app and have several util functions like this
function getSession(){
const session = ns.get('MONGOOSE_SESSION');
return session;
}
async function commitTransaction() {
const session = ns.get('MONGOOSE_SESSION');
try {
await session.commitTransaction();
console.log('Transaction successful!');
} catch (err) {
console.log(err);
}
}
async function abortTransaction() {
const session = ns.get('MONGOOSE_SESSION');
try {
await session.abortTransaction();
} catch (err) {
console.log(err);
}
}
here is how you use transactions in your queries
const result1 = await Collection1.findOneAndUpdate(filter, updateData, {
session: getSession(),
});
// updates collection 1
const result2 = await Collection2.findOneAndUpdate(filter, updateData2, {
session: getSession(),
});
// updates something in collection 2
await Collection3.deleteMany(filter).session(getSession());
// deletes something in collection 3
await commitTransaction();
/* commits all the values to the DB if it reaches here, if there is an
error , you can call the abortTransaction function in your global
error handler
*/
For every query you use a .session() or pass it as an option and then at last you commit the data.
Although transactions might make the API response a little slower than usual, having a transaction manager for all your DB calls guarantees that your writes to different collections are Atomic.
Folks at MongoDB always recommend you to keep related data at one collection since at a document level, things are atomic by default, but what happens most of the times is , you don't have a choice but to keep your data at different collection, that's when transactions can help you
Built a scheduler feature which can schedule tasks on a particular DateTime
There was this requirement in the product which I am building where we had to publish a report for students on a particular day.
This can be anywhere from 3 weeks - 4 months.
The simplest approach I thought initially was to create an API which polls the DB every minute using a CRON expression. This API could have been called via AWS EventBridge.
But for my use case,
The Reports are usually published after 1 month or in the semester's end (5th month)
We won't have more than 300 JOBS per batch(every 6 months)
so calling the API every minute doesn't make sense.
Although there are many ways of building a Scheduler,
My idea was simple, why not schedule a different job for every task(report-publish) instead of polling the DB every min.
I was searching for something which can just plug into the express server and something which is not complex.
I started looking for packages which support date-based scheduling and found node-schedule. This can run a task on a specific date.
It's this easy to schedule a job
const schedule = require('node-schedule');
const date = new Date();
date.setMinutes(date.getMinutes() + 2);
// runs after 2 minutes after this script is exucuted
const job = schedule.scheduleJob(date, function(){
console.log('The world is going to end today.');
});
Summary on how the package works internally
You basically send it the date and a callback function which has to be executed on that date. Behind the scenes the package runs the callback function with a setTimout .
Since we know that setTimout cannot run for more than 24.8611 days , this uses a package called long-timeout
This might not fit everyone's requirements, let me list down some limitations which will help you make a decision
Limitation 1: If the express app stops running or restarts, all the tasks scheduled will be flushed. (can be solved)
Limitation 2: You can't upscale the service horizontally, because there may be a case where the same task can be scheduled in two different systems. (probably can be solved)
Limitation 3: There is always a limit on how many jobs you can set up. If you plan to have millions of jobs, this might not be ideal.
Let's address how these limitations weren’t a problem for me
Fix Limitation 1: Store the Tasks scheduled in a collection

Whenever you schedule a job, store the information required in a collection.
In your express app, there is a place called app.listen which accepts a callback function which is executed when your server is ready to handle requests. Add a function which will get all the jobs from
app.listen(port, async () => {
/* reschedules all the jobs which are in the DB
when restarting the express app */
await Scheduler.reScheduleAllJobs();
console.log(`Listening: http://localhost:${port}`)
})
Fix Limitation 2: Scaling Issues
If you have multiple instances running for the same service(codebase) then you will have the same tasks spawned in all the services.
This might be a problem especially if you are dealing with sending a notification to users. You don't want to send multiple notifications to your users for the same action.
Here are some possible fixes.
Fix 1: Handle the multiple calls scenario in your code. if 2 requests are calling to publish the report for the user at the same time, you will publish the report only if it was not published before. Your code should use some kind of lock mechanism,
In MongoDB, the update queries like updateOne and findAndModify use a lock, what that means is, if two requests are trying to update the same resource, only one can update at a time.
so you can use an updateOne query with an if a condition like, if isReportPublished is false then make it true. updateOne returns an object with a property called nModified , if this value is 0 that means the document was not updated. So we send notification and other related logic only if the nModified!=0.
Fix 2: If your code can't handle multiple jobs calling the same API at the same time for the same task, then the simple fix is to have only one job running for a particular task.
Don't scale the Service Horizontally but do it vertically. - hahaha
The chances of your service having downtime may be high, but since we restart the jobs, it should be alright (if you are okay with your jobs running a little later than expected due to downtime).
In this package node-schedule when scheduling the jobs, if the current date is greater than the scheduled date, it won't schedule the task, but in our case here, we need it to run immediately after restarting the service, if it failed. So you have to handle this and retry mechanisms, error notifications etc in your code.
You can have a separate service which just schedules jobs and runs them.
Limitation 3: There is always a cap on the number of jobs you can run
I want to share some numbers, depending on your requirements and scale, you can decide.
As I mentioned earlier, our app will not have more than 2000-3000 active jobs that are scheduled. Since we are a B2B EdTech SAAS, we usually are pre-aware of the scale.
This is mostly not the case with most of the SAAS products. But I ran some benchmarks.
Here is what I tested on a t3a.medium (AMD EPYC 7000 - 4GB RAM 2Core) EC2 Machine
90K Jobs to be executed at a different time in the future and 10K Jobs to be executed at the same date and time.
The RAM consumption went from 60MB to 140MB and the CPU Utilisation was at 95% at a point since I scheduled all the 90K jobs at once.
All the 10K Jobs ran within a minute. (Running 10K jobs at once took 49 seconds ).
This is 10X more jobs than my requirement, so I am good.
Working with Microservices
Microservices are a way of building applications as a set of small, independent services. Each microservice has a specific function and can communicate with other microservices through REST APIs to perform tasks and accomplish the overall goals of the application.
For example, an app like Uber will have a different Microservice for finding a driver, handling payments, storing and managing reviews, user-related data etc.
I won't go into why to not use them or when to use them, it depends on the team size and various other things.
There are a few things I learnt that I want to share
How do services communicate with others efficiently?
Can we maintain Atomicity while working with Microservices ?
Some things I didn't like
How do MicroServices Communicate with each other Efficiently?
While there are different ways of inter-service communication with different protocols like GRPC, Event Driven, Thrift etc., we followed the REST HTTP approach.(Behind the scenes uses HTTP2).
Simple Answer:
They communicate with API calls that doesn't have to go through the internet. That's it
You expose an endpoint and the consumer services call the API.
Importance of having a Mapping of ServiceNames, PortNumbers and BaseURL
While working with micro-services, there must be some code/package which handles the inter-service calls easily for you.
It should have a mapping between all the service names, with their port number.
For the local communication, the port and other things can be from the mapping but for other environments, we can take the necessary values from the env variables/ AWS secrets manager.
You need to call this function to get the appropriate URL. Something like the getUrl function below.
function getServiceUrl(serviceName: string, endPoint: string) {
// if we want only one of the services to point to local
const localUrlExists = process.env[`${serviceName}_URL`];
if(localUrlExists?.length){
return localUrlExists;
}
const isLocal = process.env.isLocal;
if (isLocal) {
const port = getPortNumber(serviceName); // stored mapping
const baseUrl = constructBaseUrl(serviceName, isLocal);
return `http://localhost:${port}/${baseUrl}/endPoint`;
} else {
const domain = process.env.domain;
const baseUrl = constructBaseUrl(serviceName, isLocal);
return `https://${domain}/${baseUrl}/endPoint`;
}
}
function constructBaseUrl(serviceName: string) {
// specific to your org.
const version = process.env.version;
const name = getServiceBaseName(serviceName); // a mapping
return `api/${version}/name`;
}
function getPortNumber(serviceName:string) {
const portMap = {
userService: 4045,
mapService: 4046,
};
if (!portMap[serviceName]) {
// throw Error
}
return portMap[serviceName];
}
The idea is, Each services can be on the same domain while they have a different path.
At our company we have a separate internal package which holds this mapping information.
Imaginary Example:
https://uber.com/api/v2/userservice - points to userservice
https://uber.com/api/v2/reviewservice - points to review service
Isn't it Slow ?
Isn't it slower, if we are making API calls over the internet for interservice communication?
Yup. But we won't make the calls through the internet from a public DNS.
We create a private DNS entry for the domain to the Internal Load Balancer which routes the traffic internally as if two services are talking to each other while they are running locally.
so the service when making an API call checks
if there is any private DNS record for the domain
if yes, it routes the traffic to an internal load balancer
internal load balancer decides what instance will handle the request (based on rules like round robin etc) and get the resource directly from that instance without calling it through the internet
If you have not configured a Private DNS and the Internal Load balancer, then the traffic will go through the normal Internet(slow).
Overall Overview for setting up a new service
You have to Create a Mapping in the internal package.
Update the package in every other service, or in the service where the new service will be used, to begin with
Create a New Codebase with the mentioned BaseURL before the api starts ("/api/serviceName" ) and instal required packages.
Do the necessary Infra changes like adding the baseURL mapping to the deployed service.(Don't have that deep understanding about this)
If this is the first service, then you have to setup an external Load balancer, Internal Load balancer, Private, Public DNS and maybe some other steps which I might have missed.
Now imagine, every time you have a new environment like Staging or UAT, you have to do this all over again.
This is why I was saying if you are a small team, Just keep it monolith until you hire someone who takes care of these things. (probably a nice place to plug Qovery)
I have personally never touched the infra side of things but my architect was sweet enough to show me how these things were setup when I asked questions around this.
Few things which are annoying in Microservices
Let's say your PM want's a new feature like showing some extra data in a couple of pages.
For them it's just showing simple data in 2 pages, but for you,
you might have to modify 3-4 services,
get your code reviewed for all the services ,
make the necessary frontend changes
and get it merged to all the required branches. Oh dear this video is accurate 👇🏻
Also, Did I forget about test cases?
I am a big believer in unit testcases. It might not be helpful when you are developing the code but oh boi when you are refactoring the code and want to check if all the API's are working fine, this is a huge saver.
But another pain is, you have to write testcases independently and mock the API response. If there is a change in the API response, you have to go in and change the testcases in all the other servies which are consuming it.
Should we ensure Atomicity in Microservices ?
Sure yeah, why not.
If you are updating something to 3 different services and one of them failed to respond, you ideally should not make the changes in all the remaining services. But this is hard and slow.
I think the term is called Distributed Transactions. Well in my current workplace we haven't implemented something like this because it adds more overhead, plus might add a single point of failure.
So No, We don't maintain Atomoicity through services but we maintain Service Level Atomoicity using MongoDB and hope for the best.
await saveDataInCourse({ endDate }); // interservice call
await Quiz.updateOne({ quizId:"adsa"}, { $set: { endDate } }, { session: getSession() }); // updates the value in the service DB with sessions
await commitTransaction(); // commits the transaction when the function is called
Something like this where we are making an interservice call to save the quizData and then storing the quizData in the DB.
If the inter-service call fails, our Quiz Data doesn't save because the code won't reach commitTransaction where the actual commit happens to the DB - Good
if our inter-service call works but the QuizData.updateOne fails for some reason - Cry
I have not faced this issue though, But yeah before having any interservice logic, we can make sure our data which needs to be updated is validated in the code level and the DB mostly won't fail is what you can hope for. (especially if it's a managed service like atlas). Let me know, how you will handle this.
Working with MongoDB
MongoDB was the second NOSQL Database I tried after Firestore. It is similar to firestore but has so much more to offer like complex aggregations and compound indexes. (Both of which I have not worked on with firestore)
I have learnt a bunch of things while working on mongoDB from over an year.
Schema Design tips
Let's start with basics, The idea of designing Schema's is simple
Store data in a way you want to query data.
While SQL recommends you store Data in a Normalized Form (Keeping Data in seprate Tables without Redundancy ) . MongoDB let's you be free, keep all the data at one place if it's queried that way, no one will ask.
Let's say you want to keep all the grade information of a student with his attempt information.
{
userId: "123",
attempts: [ { attemptId: "456", attemptName: "sda" }]
userName: "Hsb"
}
Indexes - The ESR Rule
A MongoDB index is like an index in a library, but for a database. It helps the computer find things in the database more quickly. Instead of going through the entire library to find your book, you know where your book is located through an index.
This is the only thing I knew when I started working with MongoDB. I had created a bunch of primary indexes for a couple of collections, I knew they were fast and consumed memory to store them.
But at some use cases at my work, just querying with one field was not enough, there were multiple fields in the query.
let's say you want to query all the PRO Users from Bangalore.
db.collection.find({ membershipType: "PRO", location: "Bangalore"})
Assuming we have added an index for membershipType, this will be fast but mongo has to still filter out the records for location:"Bangalore" without an index. That means if there are 10,000 users with 500 Pro users and 10 Pro users from bangalore, the Index will definitely help us limit the data to 500 records but it has to still filter out and get you just 10 users in memory.
That's why we create a compound index like
{ membershipType:1, location:1 }. Mongo will return just 10 users using the index.
Now if you want to get the latest Pro users from Bangalore and assuming you are having a field called createdAt, then you should create an compound index with
{ membershipType: 1, location: 1, createdAt: 1 }
db.users.find({ membershipType: "PRO", location: "Bangalore"}).sort({ createdAt: -1 })
Now if you want to get the latest Pro users from Bangalore who have spent more than 150K in total, then your query will be like
db.users.find({
membershipType: "PRO",
location: "Bangalore",
amountSpent: { $gt: 150000 }
}).sort({ createdAt: -1 })
If you are thinking to add an index like { membershipType: 1, location: 1, amountSpent: 1, createdAt: 1 }
you might not get the optimal results. The right way to do this is like this
{ membershipType: 1, location: 1, createdAt: 1, amountSpent: 1 }
Yes, the order matters. It's based on a Rule called ESR.
Equality , Sort , Range.
membershipType: "PRO" is the equality match
.sort({ createdAt: -1 } is the sort
amountSpent: { $gt: 150000 } is the range operation
Our compound indexes should follow this rule to get data in the most efficient way.
Don't just add compound indexes everywhere, if you know that with a single index or a compound index with less fields is going to filter data with less records then you don't have to create index for all the terms for the query.
Adding Index to Array of Elements
MongoDB suggests you to have related data in one place.
Imagine that there is a quiz which can have a bunch of questions with this schema.
{
quizId: string,
questions: [{ questionId: string, marks: number, title: string }],
.......
};
Now if you want to see, in how many quizes the same question is used ? You can write a query like
{ "questions.questionId: "123" } // searching for the questionId 123
This will scan the entire document if it’s not indexed. Here is how you can create an index for this using mongoose
schema.index({ "questions.questionId": 1 });
This was a total new discovery for me.
(Also, the above was just an example to show array of elements index, instead of querying it with an index, I would just store and increment the count in the questions collection whenever it’s used in an quiz)
The concept of having correct indexes has helped me improve the performance of multiple data fetching API by effectively indexing the values.
Aggregation
Aggregation is a powerful framework in mongo which can help you get complex computed data right from the database.
You won't need this unless you have to show some complex data which comes different places like in a dashboard or need to format data in a particular way. You write a series of pipelines for operations and it finally works.
While skimming through the codebase in the first week of my joining,
I was weirded out about what's happening seeing some crazy aggregation pipelines. I was scared of it to be honest.
After few months, I had to use aggregation for a feature and discovered this playlist on Aggregation from Codedamn and this totally gave me the confidence/motivation to get started.
Then started exploring it more and started playing around with it using the MongoDB Compass Aggregation Tab, This is such a good thing in MongoDB Compass. You can visualise what each pipleine is doing
I will share a step by step guide into getting started with aggregation in my other post, coming soon :)
Built a Notion to Blog using the Official Notion API
I have a side hustle called tapthe.link which can redirect people directly to the youtube app instead of youtube.com while sharing links on Tiktok.
I wanted to explore writing some articles for boosting SEO and also wanted to learn something new.
Why Notion ?
I spend a lot of my time on notion every day, so something like notion to Blog is what I was looking into.
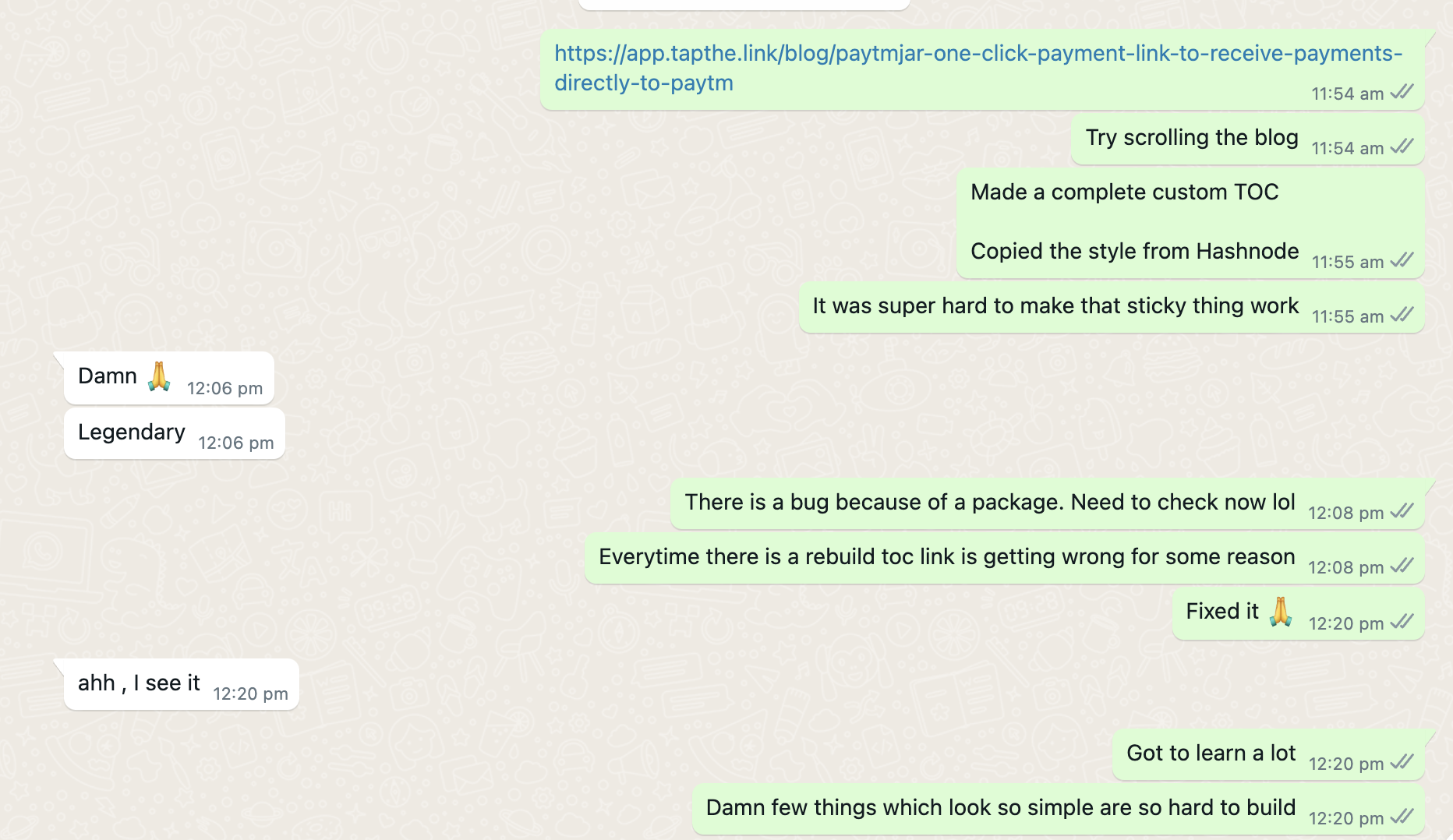
So 10 months back, I built app.tapthe.link/blog , where I just update something in my notion page and it's reflected the site within 5 minutes.
Features of the Blog
Custom CTA at the end of each blog which comes from notion, if enabled
Custom OG Images compatible for all social media platforms
sitemap and robots.xml
Table of Contents (straight out copied the UI from hashnode because of how good it is, I hope they don't mind 🙏🏻 )
The implementation used notion's Official API
-> The API returns data in JSON blocks
-> That get's converted into Markdown using Notion-to-md
-> Uses different Rehype plugins to format to HTML
-> Uses Custom Code to generate TOC
-> Get styled with tailwind typography
-> Blog Ready.
If you want to build your own notion to blog, check this repository out. You can add other custom features on top of this.
Why didn't I just use Rehype TOC ?
Well, I did that in the first, it just took me to 3 minutes to add a TOC. I was mind blown by how easy it is to add a TOC. But the UI sucked
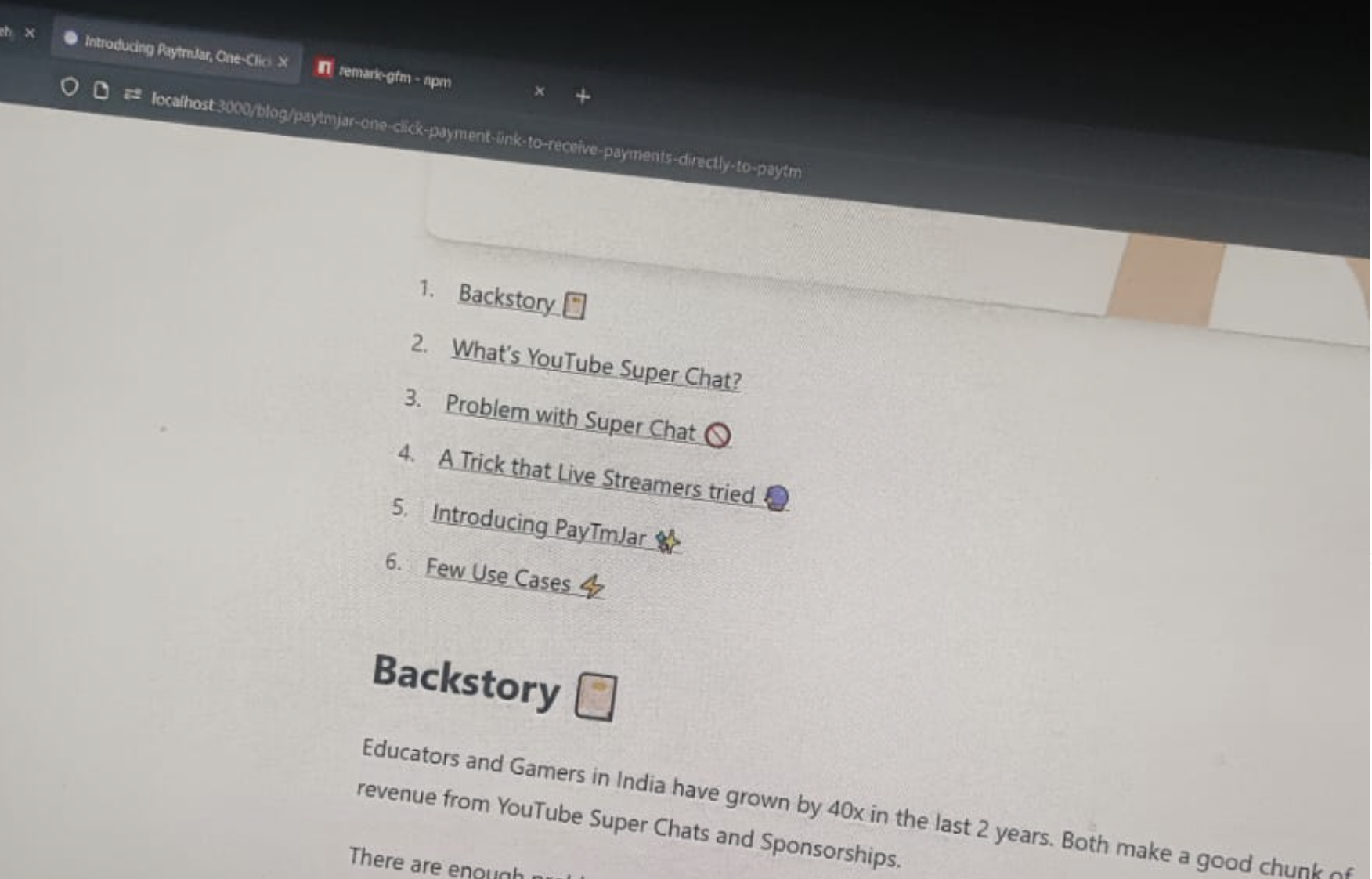
In my mind, I wanted a TOC just like hashnode and I coudn't figure out how to customise Rehype TOC to make it look and work like that.
That's why I added my own custom logic which will parse the markdown, form the structure I need to build a TOC and then uses getBoundingClientRect to get the height after which the the TOC Dropdown has to be closed. It's not as perfect as hashnode, but I didn't want to spend a lot of time perfecting it since I had already spent a good 4-5 days on making this work.
Shoutout to my friend rahul who is there to listen to me share everything I build lol.
Improved Performances of API's
While working on a particular feature on top of an existing module I started noticing that the API was really slow and there was something really bad happening there.
I didn't really do some black magic and made things faster, just did some basic optimisations and brought down the API response times from 3-6 seconds to 200ms in one of the API. I have already written about it here in my previous blog post.
It was basically , Right Indexing + Reducing Time Complexity + Reducing Bandwidth by projecting only required fields + Concurrent GET Calls wherever possible.
Learnt about Pre Commit Hooks
We use swagger to document our API. It basically allows you to document your API's by writing some lengthy ass structure like
wait, let me show you.
Here is an API to fetch users from a particular location.
/**
*
* @swagger
* /api/userservice/users/?location={location}:
* get:
* summary: Fetch Users from a location
* tags: [Users]
* parameters:
* - in: query
* name: location
* schema:
* type: string
* example: false
* required: true
* description: location of the user
* responses:
* 200:
* description: Successfully retrieved the user
* content:
* application/json
*/
This is how much code you have to add for a simple user fetching API from a location. This is used in most companies.
Now if you make any indentation mistakes or miss a semi column , the code build won't happen.
What used to happen is sometimes is ,
I used to make some silly mistakes like missing a semi column while writing the swagger doc and before pushing the code , I was not generating the docs everytime to verify if my documentation code was proper. The code used to get to develop and the deployment used to fail.
Why ? - There was a semi column missing haha
There is something called husky which will let you add some commands to be run before you commit your code to git. I added this command
npm run generate-docs
// will genereate docs if the syntax is proper, if not will throw error.
Has saved me so much of trouble.
Started Writing Unit Test Cases
Here is what Unit test cases are,
you as a developer will write some positive and negative test cases of your API.
Something like, if your API is expected to send a "pong" message when you send it "ping" and you receive the same message while running the API, the test was successful.
Some other testcase can be like this, If someone sends pingg instead of ping, your API will throw error like "Unkown Input" with 400 status code. If you get the same error message while sending the same input then your test was succeeded.
Initial Reaction
Oh boi, I felt like I am wasting a lot of time on this, what can go wrong ? In 10 days sprint , I need to develop features + also write testcases for the expectations which is already in my mind, what a waste of time.
Then came a refactor. Oh boi, unit test cases saved so much time. What do I mean ?
Unit testcases makes your code more maintainable for the future,
Let's say, If some other developer touches something and breaks it in the code to fix a bug which has impact on a lot of API's. When running the tests, all the API's which have dependency will fail. You realise you have made a mistake .
Downside: On every feature improvement, you have to not only develop new features but also change the testcases in all dependant APIs.
How to do it ?
You can write unit testcases with the help of Two Libraries, Mocha and Chai.
Here is an example
import { expect } from "chai";
import "mocha";
const httpClient = axios.create({
baseURL: 'https://my-api.com/api/' // your baseurl
});
describe("Create a Bookmark for a Content", async () => {
const courseId = Utils.generateUuid();
const contentId= Utils.generateUuid();
before(async () =>{
await createContent(courseId, contentId);
});
it('throws an error if course is not provided', async () => {
await verifyAsyncError(
`400 - "courseOfferingId may not be null, undefined or blank"`,
async () => {
const result = await httpClient.post(
'/bookmarks/',
{
elementId: elementId,
},
{
headers: {
authorization: jwttoken,
},
}
);
}
);
});
it('sucessfully creates a bookmark for content ', async () => {
const result = await httpClient.post(
'/bookmarks/',
{
courseOfferingId: courseOfferingId,
elementId: elementId,
},
{
headers: {
authorization: jwttoken,
},
}
);
expect(_.isEqual(elementId, result.elementId));
expect(_.isEqual(true, result.isBookmarked));
});
after(async () => {
await httpClient.delete('/bookmarks/clear-depencencies', {
headers: {
authorization: jwttoken,
},
});
});
function verifyAsyncError(expectedErrMsg, callback) {
let errMsg = '';
try {
await callback();
} catch (err) {
errMsg = err.message;
}
let substringMatch = errMsg.indexOf(expectedErrMsg) !== -1;
if (!substringMatch) {
console.error('Expected:', expectedErrMsg);
console.error('Actual:', errMsg);
}
chai_1.expect(substringMatch).to.be.true;
}
There are Three Things you need to know.
Describe - Describes a Feature you want to test
before/after - What has to be done before and after running the testcases
it - It's a function which accepts a description and a callback function to be executed.
But do note that,
If running testcases is not in your pre-deployment procedure and your developers are not updating their testcases on every feature improvement, then it's as good not keeping them in the codebase.
Data Patches in Production
So I don't know if I mentioned earlier, but I work at an EdTech company and we offer our LMS to some B2B Clients. Now sometimes few of these customers want to get their old data migrated to our LMS.
Something like
"We have these students who have taken the quiz on google form, and we want this to be imported to the LMS".
Or
"We have received the submission offline on google drive and want that to be imported to the LMS"
So a script should get this data from their excel sheet, convert it to the format your LMS expects, add all the dependencies like metadata etc and finally make it work.
This was a super fun and challenging task. Loved it
End
Now that I look into the past while writing this article, I have learnt a lot of new things, it's just the beginning, my stomach is not filled, I am hungry for more.
What's for 2023 ?
I want to build more useful tools like tapthe.link
I want to explore React Native and want to go deep into reading research papers and engineering blogs :)
If there is something here which you don't agree or is wrong, you can let me know, I am still a newbie and it's still day one for me.



